AS YOU READ, RELATE WITH BELOW QUESTIONS. IT WOULD BE FUN ...
- 1. Why deep attention layers have so much redundancy?
- 2. Why joint-drop works better in high sparsity cases?
- 3. Why quantization enhance efficiency of these methods?
- 4. Why joint-drop excel attention-drop? (an easy one)
- 5. Why one-shot drop excelled iterative drop?
Introduction
The famous work ATTENTION IS ALL YOU NEED has been the basis of a lot of Transformer-based LLM progress and AI research. Transformer-based LLMs have presented amazing capabilities in multiple tasks. Scaling these models has demonstrated performance along with inflated deployment costs and compute resource demands.
The paper WHAT MATTERS IN TRANSFORMERS? NOT ALL ATTENTION IS NEEDED , shares their investigation on redundancy in different modules of Transformer - MLP layers, Attention layers and Block modules. Also it proposes Attention Drop and Joint Layer Drop methods to increase the model speedup without compromising its original performance. The Attention layer facilitate contextual information flow between tokens. The MLP layer transforms the token representations.
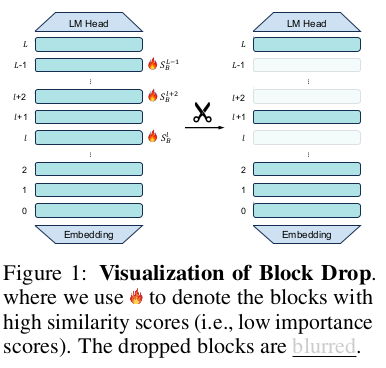
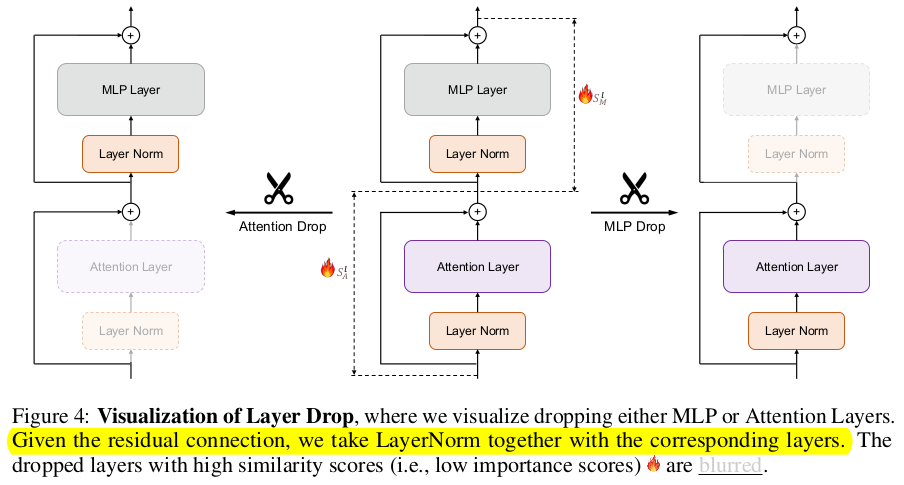
From the below image, we can understand that a (block) or (Layer+LayerNorm) is fully removed
Then, the remaining (blocks) or (Layer Module), adjusts the respective skip-connections and input outputs links.
|
|
Blurred parts represent dropped Blocks & Layers.
Block Drop degrades the model's original performance significantly with increased speedup. This is because it overlooks the internal fine-grained architectures within each block.
MLP Layer Drop also gives huge performance degradation with moderate speedup. This is because of little redundancy(more importance) in MLP layer modules.
But in attention layers, redundancy is significant, particularly in deeper layers, and is consistent across training stages.
So, Attention Layer Drop gives minimal impact on original performance with high speedup.
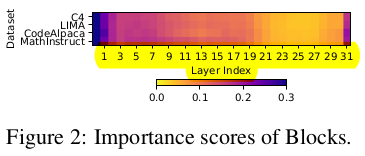
By looking at range of light yellow color(less importance score), it is obvious that attention layer have most redundancy.
|

|
Lighter the color, less the importance score, which means deeper modules are redundant.
Block Drop and Layer Drop's integration with quantization significantly enhances efficiency. This happens possibly because of increase in sparsity after quantization(fp16 mentioned in paper).
Methods
[Similarity Metric, One Shot Dropping, Training Free manner, Post-training dropping]
CORE IDEA : The important modules are expected to significantly alter their input, while the redundant modules produce outputs similar to inputs.
Thus, modules with very high cosine similarity(X,Y) are redundant modules.
The importance score S is computed as: S = 1 − CosineSim(X,Y)
where,
CosineSim(X,Y) is Cosine Similarity between the input X and output Y of the module.
Read the algorithm of two proposed methods below :
| ATTENTION DROP | JOINT LAYER DROP |
|
1. Calculate importance score for each Attention Layer module. 2. Define a dropping ratio(DR).[0-100%] 3. Prune Attention Layers with least importance scores. (according to DR) |
1. Calculate the importance scores for both attention layers(SA) and MLP layers(SM) individually. 2. Concatenate the scores into a single array: S = [SA, SM] 3. Define a pruning ratio(DR).[0-100%] 4. From the combined set of importance scores, drop the layers with the lowest values, regardless of whether they are attention or MLP layers. (according to DR) |
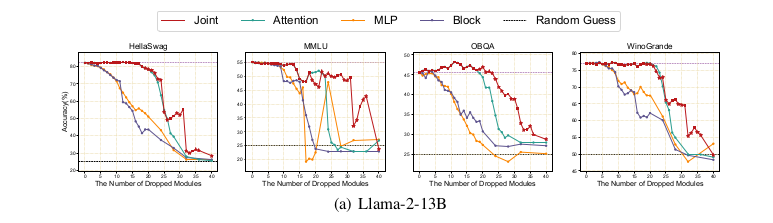
Joint Layer Drop consistently achieves better performance than either Attention Drop or MLP Drop alone.
Explanation - For same dropping ratio(d%), 'joint-drop' removes least important layers from larger set.
The 'individual layer-drop' may remove a meaningful layer(because of small set of layers) to fulfill the dropping ratio.
It can be validated from the curves in below image.
|
Evaluating Metrics for Methods
SPEEDUP DEGRADATION RATIO : SDR = ∆Avg. / ∆Speedup,
∆Avg. = the % change in average performance across the evaluated tasks,
∆Speedup = the % of speedup achieved.
SDR measures the amount of performance degradation incurred for each 1% increase in speedup.
POSITIVE EXAMPLES
- Llama-2-13B - 99% original performance, after dropping 8 attn. Layers.
- Llama-2-13B - 90% original performance(MMLU task), dropped 31 layers (Attn+MLP).
- Llama-2-70B - 97.6% original performance. 48.4% speedup.
NEGATIVE EXAMPLES
Llama-2-7B-Math model’s ability rapidly deteriorates, when Attention Layers are dropped. Reason : Instruction finetuning of Llama-2-7B-Base(originally poor in mathematics), created Llama-2-7B-Math with math ability. This ability obtained solely through FT appears to be superficial.
Wanna think more ...
- Measure of redundancy - it's validity for different transformer architectures ?
- High sparsity conditions - is it related only to model weights precisely zero ?
- Decision of one-shot vs iterative,(taken on basis of task) - any impact of architectures ?